Sproutcore MVC VS Rails MVC
Sproutcore and Rails both use the MVC pattern to organize their code bases, so their architecture must be the same right? Well, not quite. There are actually several differences between the Sproutcore MVC pattern and the Rails MVC pattern that trip people up when they're first starting to work in Sproutcore. This post is my attempt to lay out the two patterns so that their differences can be seen and appreciated.
Note: Although I'm using Rails as the example server side pattern, this actually has much more to do with server side MVC VS client side MVC. So just about anything that I say about Rails can be applied to .NET MVC, Django, etc.
Rails / Server Side MVC
I'm going to assume that most of the people reading this article are already familiar with the basic architecture of a Rails application. The following diagram shows (roughly) how a request goes through the Rails stack.
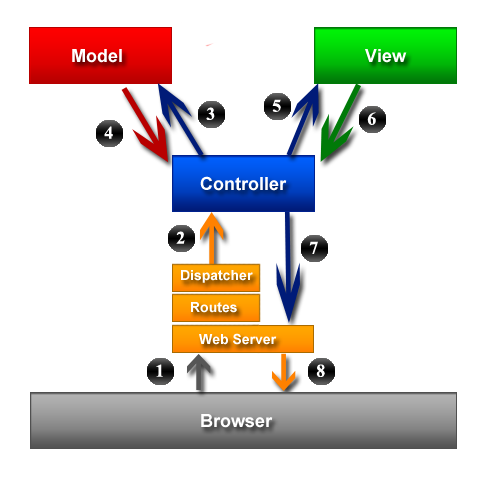
Steps
- The browser sends a request to the web server.
- The web server processes the request, determines which route it belongs to and dispatches that request to the corresponding controller method.
- The controller then asks the model layer for all the necessary information in order to be able to complete the request.
- The model layer collects all the information and returns it to the controller
- The controller gives the appropriate information to the view, and asks it to render
- The view renders itself and gives the rendered html to the controller
- The controller assembles the total page's html and gives it to the web server
- The web server returns the page to the browser
Summary
So there are a couple of key things to notice in the way that the request comes through the stack.
First, notice that there is only a single point of entry for the system. All requests are going to come into the system by the browser hitting a route, which the system parses and and does something with. The user might have clicked a button, clicked a link, browsed a certain distance down the page, etc, but the system doesn't know, and it doesn't care. All it knows and cares about is the route which the request comes in with, and then it figures out what to do with it.
Second, notice that there is only a single point of exit for the system. The system takes the route given, collects all the information that it needs, and generates a big blob of something. It could be HTML, JSON, JavaScript, XML, etc but whatever it is, the system's job is to cobble it together, and give that big blob back to the web server. Whatever the request, the response is going to be a blob of something going back to the browser.
Rails and other server side frameworks set up their MVC pattern to work this way because they're trying to deal with the fact that HTTP is a stateless protocol. Unlike the traditional MVC pattern developed in Smalltalk, the application itself (particularly the views) can not really have state. Because of this, there is no true rendering involved on the server. It's just going to receive in a request, and dump out some set of data that is going to get rendered by somebody else.
For most of us who learned MVC from Rails or some other server side framework this is MVC. It's all that we know. But in reality, this is a simplified version of the traditional MVC framework, and when we're no longer constrained by a stateless protocol we can take full advantage of the full pattern. Which is exactly what Sproutcore does with it's MVC.
Sproutcore MVC
The Sproutcore MVC framework is close to Martin Fowler's Passive View, but even closer to Cocoa's implementation of MVC. Instead of receiving a route, and generating a blob of something, the system responds to events by modifying the state of the system. Let's look at how that is structured:
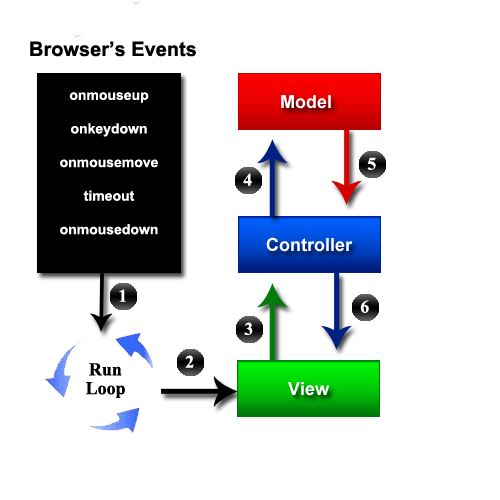
Steps
- When the browser raises a user event like a mouse down, the root responder starts up a runloop.
- The root responder gets the view that was the target of the event sends that event to the view, eventually the API for that event on the view view is called.
- That view then processes the event and calls the appropriate action in the controller layer
- The controller layer processes the action, and calls into the model layer do whatever domain action was specified, changing it's state
- The state changes that took place in the model layer are bubbled up into the controller layer through bindings between the model and it's controllers
- The state changes that took place in the controller layer are bubbled up into the view layer through bindings between the controller and the view, and the view re-renders itself
Concrete Example
In order to make this a bit more concrete, let's look at a specific example as well. Imagine that we're working with some sort of system with a volume control, and let's imagine that the increase volume button is pressed. What would that look like?
Note: In Sproutcore a click is actually a mousedown followed by a mouseup. For simplicity, we're just going to look at the mouseup part, since this is where the actions would really take place.
- The browser receives a mouseup event, and the root responder starts up a runloop. (Sproutcore automatically takes care of this step, you will never even see it)
- The root responder sends the mouseUp message to the IncreaseVolumeButtonView with the event information.
- The IncreaseVolumeButtonView checks it's state to see if it is currently enabled, finds that it is, and so it sends the increaseVolume message it's coordinating controller (this could be a literal controller, or a statechart).
- The volume coordinating controller validates that the state of the larger application allows increasing the volume at this time, finds that it does, and so it sends the model layer the increase volume message.
- The model layer then would change any external system that would need to change to adjust the volume (say a speaker), and change it's representation of that volume (maybe increasing an integer representing the volume by 1).
- At the completion of the changes to the state of the model layer, the bindings for the model layer would fire because a change had taken place, letting the mediating controller know to update itself. (Sproutcore automatically takes care of this step, you only have to setup the initial binding)
- At the completion of the changes to the state of the mediating controller, the bindings for that controller would fire, letting the views that are bound to the volume setting (CurrentVolumeView, and VolumeBarView for example) know to update themselves. (Sproutcore automatically takes care of this step, you only have to setup the initial bindings) The views then would re-render the appropriate part of themselves, ensuring that the display matches the state of the system.
Summary
Notice that the entire system now has state. In the typical server MVC like Rails, the only state that is maintained is in the model layer, and that's through a persistence store like MySQL. This is necessary on the server because you have to rebuild the entire system with each request, but on the client it isn't. Everything is generally kept in memory, and you only have to interact with a persistence store when you can't keep everything in RAM, or when you want to save the system's state.
Also, since you don't have to rebuild the entire system with each request, each layer has a current state in memory, and the job of the system is to propagate the appropriate changes given the action of the user. This allows us to build richer UIs that respond differently when they are in different states much more easily. As such, the system's job is no longer primarily about generating output, maintaining and updating it's state.
Conclusion
When I first started working on the client side the only MVC that I knew was the one from Rails, and I didn't even know that I needed to change the way that I think about MVC in order to get how something like Sproutcore functioned. Hopefully this post has at least pointed you in the right direction. If your looking for more information, I would recommend reading through Cocoa's documentation on it's design patterns (particularly the MVC section), and then look through some larger Sproutcore apps like Tasks, or OtherInbox.
Although some have attempted to bring the server side model of MVC into the client (Backbone.js's controllers for example "provide methods for routing client-side URL fragments, and connecting them to actions and events"), in the long term I think we will be better served if we learn to use the client MVC pattern for our client side apps, and the server MVC pattern for our server apps. It certainly can take some getting used to, but since we have state on our clients I think we should take advantage of it.